Artificial Intelligence is aggressively marketed as the ultimate catalyst for efficiency—a cheaper, faster, and infinitely scalable alternative to traditional workflows. Executives are captivated by stories of AI agents resolving customer tickets in seconds, chatbots handling thousands of concurrent interactions, and generative AI producing weeks’ worth of content in an afternoon.
At first glance, the economics appear irresistible. Why pay a human employee for routine tasks when an AI model can perform them for fractions of a cent?
The answer lies in a growing challenge that many organizations are only just beginning to understand: The Token Trap.
While AI pricing appears incredibly inexpensive on paper, real-world deployments frequently reveal a starkly different reality. As usage scales, token consumption, infrastructure requirements, LLMOps (Large Language Model Operations), and quality assurance expenses compound at an alarming rate. The result? Many organizations discover that enterprise-grade AI is a significant line item requiring strict financial governance.
What Exactly Is a Token?
To understand the trap, you must first understand the currency of Generative AI. Modern AI systems do not charge by the hour or by the word; they charge by the token.
A token is the fundamental unit of data processed by an AI model. Depending on the language and model, a token might represent an entire word, a single syllable, or just a punctuation mark. A standard rule of thumb for English text is that 100 tokens equal roughly 75 words.
Every single interaction with an AI model consumes tokens on two fronts:
Input Tokens: The prompt you send (including system instructions, conversation history, and uploaded documents).
Output Tokens: The response the AI generates. (Note: Output tokens are typically priced 2x to 5x higher than input tokens because generating text requires more compute power).
The Reality Check: A simple user query might use 200 tokens. But a business process analyzing documents and handling thousands of daily users can easily burn through billions of tokens a month. This is where the compounding effect begins.
A Quick Reality Check on AI Pricing
To understand why token consumption matters, it helps to look at how leading AI providers price their models. While prices change frequently and vary by model version, the table below illustrates the general economics of enterprise AI usage.
Provider
Model Family
Input Cost (Per 1 Million Tokens)
Output Cost (Per 1 Million Tokens)
OpenAI
Premium Reasoning Models
$2.50 – $5.00
$15.00 – $30.00
Anthropic
Claude Sonnet Class
~$3.00
~$15.00
Anthropic
Claude Opus Class
~$5.00
~$25.00
Google
Gemini Pro Class
~$1.25
~$10.00
Google
Gemini Flash Class
~$0.10
~$0.40
Note: Pricing varies by model version, context window, caching mechanisms, and provider-specific discounts. Figures shown are representative and intended for illustration.
At first glance, these numbers appear insignificant. After all, what is a few dollars per million tokens?
This is where many organizations fall into the Token Trap.
A million tokens may sound like a large number, but enterprise AI systems often process millions of tokens every day. Customer support assistants, internal knowledge bots, document analysis systems, coding assistants, and AI agents can collectively consume hundreds of millions—or even billions—of tokens per month.
At that scale, what initially appears to be a negligible API expense can rapidly evolve into a meaningful operational cost requiring active governance and financial oversight.
The Hidden Multipliers: How Token Inflation Happens
Many businesses calculate their ROI based solely on the visible API cost of a single prompt and response. However, actual deployment costs are driven by invisible multipliers.
1. The Burden of Conversation Memory
Large Language Models are naturally “stateless,” meaning they don’t remember past interactions unless you remind them. To maintain a natural, continuous chat experience, applications must repeatedly feed the entire conversation history back to the AI with every new user message.
A customer support chat that starts at 500 tokens might swell to 8,000 tokens by the fifth back-and-forth exchange. Organizations end up paying for the exact same information multiple times.
2. Retrieval-Augmented Generation (RAG) Data Dumps
Enterprises rarely use AI in a vacuum; they want the AI to analyze their proprietary data—contracts, HR policies, financial reports, and knowledge bases. To do this, systems retrieve relevant chunks of company documents and paste them into the AI’s hidden prompt. Processing thousands of pages of context to answer a single question causes input token usage to skyrocket.
3. “Agentic” and Multi-Step AI Calls
What looks like one click to the user is rarely a single AI operation on the backend. A sophisticated enterprise request often triggers a cascade of hidden AI calls:
Intent Analysis: What does the user want?
Query Generation: Formulating a database search.
Response Generation: Drafting the answer.
Safety & Formatting Validation: Checking the output for compliance.
4. The Premium Model Migration
Organizations frequently pilot projects with smaller, cheaper models (like GPT-3.5 or Claude Haiku). But as users demand higher accuracy, better reasoning, and fewer hallucinations, companies are forced to migrate to premium “frontier” models (like GPT-4o or Claude 3.5 Sonnet). Performance improves dramatically, but the cost per token can jump by 10x to 30x.
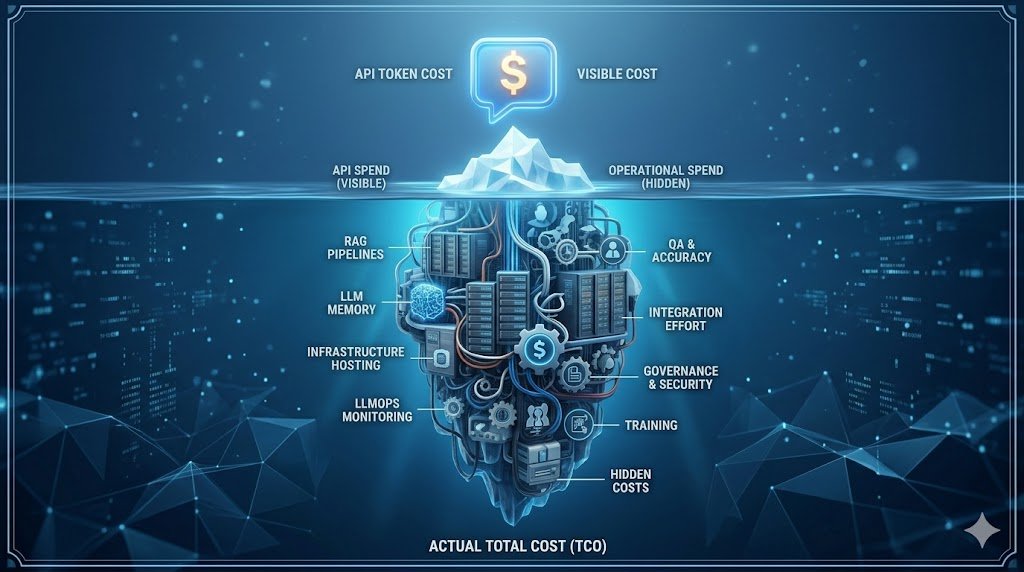
The Cost Beyond Tokens: The AI Iceberg
Token pricing is merely the tip of the iceberg. To deploy AI securely and effectively, organizations must account for a massive layer of operational overhead beneath the surface.
Integration & Middleware: Connecting AI to CRMs, ERPs, and internal databases requires significant custom engineering and API management.
Vector Infrastructure: Building searchable “memories” for AI requires specialized vector databases (e.g., Pinecone, Milvus), which come with their own licensing and cloud hosting fees.
Governance and LLMOps: AI outputs are probabilistic, meaning they guess the right answer. Monitoring systems for accuracy, compliance, bias, security, and hallucinations is mandatory—and often requires keeping “Humans-in-the-Loop” (HITL), negating some of the labor savings.
Change Management: Employees must be trained in prompt engineering and new workflows. The organizational shift requires time, curriculum development, and leadership bandwidth.
A Realistic Scenario: Expected vs. Actual Costs
Imagine a mid-sized company deploying an AI assistant for 500 employees. Here is how the initial business case often falls apart:
Expense Category
Initial Management Estimate
Actual Post-Deployment Reality
Base AI Subscription
₹2,000 per user/month
₹2,000 per user/month
Context/Memory Bloat
Not factored
+₹800 per user/month
Cloud & Vector DB Hosting
Assumed negligible
₹1,50,000 / month flat rate
LLMOps & Monitoring
Not factored
₹75,000 / month flat rate
Integration Maintenance
Built-in to IT budget
Requires 1 dedicated engineer
Total Monthly Cost
₹10,00,000
₹16,25,000+(~60% Increase)
The original estimate rarely reflects reality. The technology still delivers immense value, but the unit economics look fundamentally different than promised.
Does This Mean AI Is Too Expensive?
Not at all.
In many situations, AI delivers extraordinary, compounding value. It breaks down data silos, accelerates decision-making, supercharges coding, and provides infinite customer service capacity. The problem is not the AI itself; the problem is unrealistic cost expectations.
We have been here before. A decade ago, Cloud Computing was marketed purely as a cheaper alternative to on-premise servers. Companies blindly migrated, only to be hit with massive, unexpected AWS or Azure bills. This birthed the discipline of “Cloud FinOps.”
AI is entering the exact same phase. We are now in the era of AI FinOps.
Avoiding the Token Trap: Strategies for AI FinOps
Organizations that succeed will treat AI spending with the same rigorous discipline applied to cloud infrastructure. You can rein in costs by implementing these safeguards:
Model Routing: Don’t use a sledgehammer to crack a nut. Route simple tasks (like summarization or data extraction) to cheap, fast models, and reserve premium models strictly for complex reasoning.
Implement Semantic Caching: If 100 users ask the HR bot “What is the holiday schedule?”, the AI shouldn’t generate the answer from scratch 100 times. Cache the first response and serve it to subsequent users for free.
Optimize Context Windows: Enforce strict token limits on conversation history. Summarize older chat logs rather than feeding the entire raw transcript back into the model.
Govern and Monitor: Use dashboarding tools to track token consumption by user, department, and application. Implement hard caps to prevent runaway loops.
Conclusion
Generative AI is undeniably transforming how organizations operate, but its economics are far more complex than a standard software-as-a-service subscription.
The most expensive mistake a business can make is assuming that basic token pricing equals the Total Cost of Ownership (TCO). In reality, tokens are only the entry fee. As AI adoption scales, leaders must aggressively account for infrastructure, governance, integration, and operational bloat.
The companies that dominate the next decade will not necessarily be the ones that use the most AI. They will be the ones that architect it efficiently, understand their unit economics, and manage the Token Trap before it manages them.
The next wave of enterprise AI success will not be defined by who deploys AI first. It will be defined by who understands the economics best. In the same way cloud computing created FinOps, generative AI is creating a new discipline of AI cost governance. Organizations that master it will gain a lasting competitive advantage. Those that ignore it may discover that their biggest AI challenge was never accuracy—it was affordability.


")






 | Volume 2")

